
The LMBM lexicon is exclusively the domain of lexemes which are defined specifically as noun, verb, and adjective stems and the lexical categories which define them (Number, Gender, Transitivity, and so on). All other meaningful material must belong to the closed set of closed categories of grammar and are handled by 'morphology' in the general sense (derivation plus affixation). LMBM, then, distinguishes itself from other lexeme-based theories in that it maintains a pristine distinction between lexemes and grammatical morphemes and consequently predicts this distinction at every level of language and speech.
Lexeme-Morpheme Base Morphology (LMBM) is a variant of what Aronoff (1994) refers to as a 'lexeme-base' morphological theory. Lexeme-base morphology assumes that only the lexeme is a true linguistic sign where 'lexeme' is defined exclusively and explicitly as any and all noun, verb, and adjective stems. The effects of lexical and inflectional derivation on the lexeme do not affect its status as a sign at all. These processes, it follows, must involve elements other than linguistic signs.
Lexical (derivational) and inflectional morphemes hence must represent different types of linguistic elements. The fundamental claim which distinguishes LMBM from other morphological frameworks is its rigid distinction of lexemes and (grammatical) morphemes, hence its name, 'Lexeme-Morpheme Base Morphology.' Beard (1988, 1995) argues that grammatical morphemes differ from lexemes in the following ways (detailed arguments may be found in 'LMBM and Word Syntax' at this website)
If lexemes are noun, verb, and adjective stems, and if they are the only objects stored in the lexicon, it is natural to ask what determines or generates grammatical morphemes. Grammatical morphemes are the output of purely phonological operations independent of the semantic (grammatical) operations which they mark ('realize'). This conclusion is the Separation Hypothesis.
The Separation Hypothesis splits all derivation, inflectional and lexical alike, into three processes: lexical (L-) derivation, inflectional (I-) derivation, and morphological spelling. Derivation involves operations on abstract lexical and inflectional category functions such as [+Plural, -Singular], [+Past, -Present], [+1st], and the like. Spelling is the purely phonological realization of the morphological categories of any base lexeme which has undergone such derivation. Its function is to distinguish stems which have undergone derivation from those which have not. If the derivation is inflectional, the marker may be attached to the lexical stem or assigned independently to a structural position in syntax in ways which syntax alone cannot predict.  For example, [+Definite] singular nouns in Swedish are suffixed, but [-Definite] singular nouns are marked by the same morpheme in a free position, e.g. en katt 'a cat' vs. katt-en 'the cat'. Hence, the LMBM lexicon contains neither bound nor free grammatical morphemes –– both are the responsibility of morphological spelling. The layout of an LMBM grammar is illustrated in the table to the right:
For example, [+Definite] singular nouns in Swedish are suffixed, but [-Definite] singular nouns are marked by the same morpheme in a free position, e.g. en katt 'a cat' vs. katt-en 'the cat'. Hence, the LMBM lexicon contains neither bound nor free grammatical morphemes –– both are the responsibility of morphological spelling. The layout of an LMBM grammar is illustrated in the table to the right:
What then are 'morphemes' under this hypothesis? Bound morphemes include affixes and other modifications of the phonological representation of a lexeme, such as reduplication and (Semitic) revoweling, the spelling out of articles, auxiliaries, adpositions--any expression associated with a grammatical category or relation rather than a semantic one.
Under LMBM, L-derivation takes place in the lexicon. Here lexemes with new lexical meanings are formed from from underived lexemes. Inflectional derivation, following the arguments of Matthews (1972), Anderson (1982), and Aronoff (1994), takes place in syntax. Both these derivational types are phonologically realized by an autonomous morphological spelling component located after all syntactic rules but before any phonological rules operate.
Unlike free morphemes, then, bound morphemes are phonological modifications (only) of the phonological representations of lexemes which mark the fact that the lexeme has undergone lexical or inflectional derivation (the Empty Morpheme Entailment). Neither type of morpheme has any meaning and thus morphemes attribute no meaning to the stems to which they attach. All meaning is accounted for by the derivation rules. This immediately explains empty and zero morphemes. Empty morphemes represent affixation without derivation; zero morphemes are derivations without affixation. Morphological asymmetry, the many-to-one and one-to-many mappings of morphological forms to function is also explained by Separation.
Free morphemes, on the other hand, may require syntactic positions since they are ostensibly subject to movement and also often belong to paradigms. I have in mind now such morphemes as free adpositions, auxiliaries, conjunctions, and pronouns. All but conjunctions are themselves subject to inflection. Pronouns like which and who, as well as free auxiliaries seem to move from one syntactic position to another in some languages. However, even the positions of auxiliaries and pronouns usually conform to Anderson's General Theory of Affixation, which LMBM also assumes. Moreover, movement may simply be the phonological realization of grammatical morphemes in positions other than that in which the morphological features determining such realization appear (Beard 1995).
Derivation rules operate in the lexicon (L-derivation) and in syntax (I-derivation). The illusion of a direct relation between the sound and meaning of affixes is the result of two facts. First, derivation rules and realization rules operate on the same lexeme during the generation of a derived word. This means that affixation will correspond to the modified features in the stem. (The original features of the stem will also be modified, neutralized, so that they will not trigger affixation.)
That the order of affixes generally, but not always, follows that of the features in the base. The assumption of sign base morphology (Saussure 1916), results from the fact that the default procedure for the MS (spelling) component is to realize features in the order in which it encounters them. You may see an illustration of derivational and spelling operations by clicking here. However, feature order is often irrelevant, as in the case of affixes which can precede or follow some other affix, and cumulative exponents, which realize two or more features simultaneously.
Beard (1988, 1995) describes four types of L-derivation: transpositions, functional derivation, feature switches, and expressive derivation. Transposition simply changes the lexical class (category) of a lexeme, e.g. N to V, A to N. Functional derivations add a semantic(ally interpretable) category function, such as Subject, Object, Locus, Manner, to the featural inventory of the base lexeme. Lexical switches modify the value of inherent lexical features such as those of Gender, Number, and Paradigm Class. Finally, expressive derivations, such as Diminutive and Augmentative, reflect the speaker's attitude in ways still not clearly understood.
The Subjective (Agentive) nominalization, e.g. bake : baker, is a familiar L-derivation. It invokes three of the four L-derivation types, a functional derivation illustrated in (1-3), a transposition, whose output is (3), and a featural switch, whose output is illustrated in (4) below:
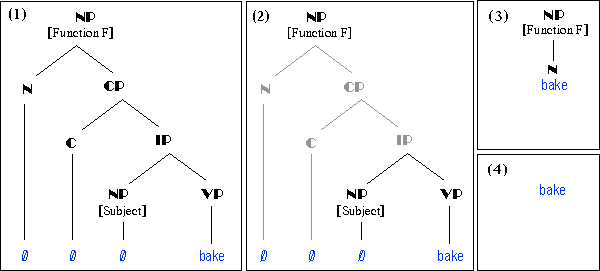
(1) is a simplified illustration of the underlying form of an NP with a relative clause, the origin of all nominalizations under LMBM. The problem is that for all the structure, only one phonologically realizable lexeme has been inserted. The lexicon has two options:
If the lexicon chooses the former tack, the superfluous structure marked in (2) is eliminated (3). The result is a single V incorrectly positioned under an NP. When this occurs, the lexicon's job is to transpose the illegal category to the legal one, i.e. provide the verb with nominal category functions (4). (4) also shows the effects of the feature switches, which sets the functional features added by the transpositions. The output of this series of processes is then submitted to morphological spelling (the MS-module), similar to 'Spellout' in related models.
Of course, the lexical description of the verb bake is preserved in the deivation and will continue to determine government and binding properties. This is illustrated in the animated version of the Subjective Nominalization below.
This set of assumptions accounts for the following facts.
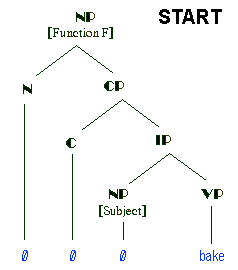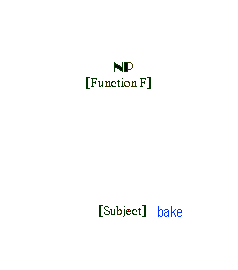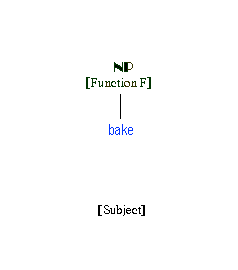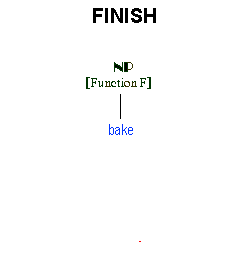
Now that we have followed a lexical derivation, let us examine an inflectional one operating on the same underlying form as (1).
If the lexicon decides not to operate on a structure such as that in (1) above, and does not collapse all that structure into a single word, it must license all the nodes which pass through it for syntax; that is, it must assure that all NPs are headed by acceptable Ns, all VPs, by Vs, all APs by As. This is apparently the role of pronominals. Pronominals are also tightly constrained by LMBM: categorically, they may only contain those lexical categories determined by the lexicon and the inflectional categories found in syntax. No other type of semantic or grammatical category may be found in a pronominal (proadjective, pronoun, proverb). However, the processes of transposition and feature switching provide precisely the categories demanded by the empty nodes in (1) and these categories are necessary and sufficient conditions on the semantic interpretations of pronominals.
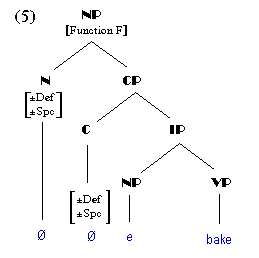
If no L-derivation applies to (1), it will be provided with the lexical categories of Gender, Noun Class, and Number from the lexicon. (Animacy is derivable from Natural Gender; see Beard 1995a.) If no L-derivation applies to (1), these pure lexical categories, along with the inflectional categories of the Subject NP, will be raised to C by wh-movement, and the output of (1) from syntax will be, roughly, the structure illustrated in (5).
Syntactic structures like (5), as well as lexically derived structures like (4), are then subjected to the phonological realization rules of the morphological spelling or 'MS' component. LMBM postulates only one integrated MS component for both lexical and and inflectional derivations.
Morphological spelling (MS) comprises the phonological realization rules of morphology. These are rules which determine the modification of lexical stems, if any, conditioned by the presence of derivational features. The MS module can read any features of a lexeme but can modify only the phonological (P) representation (denoted by blue in the figures). It must contain a short-term memory component which can hold several features before writing to the P-representation of the lexeme. This accounts for the fact that a single affix can represent several grammatical features (cf. Latin rexisti above). MS memory will have to collect the features [+Active], [+Indicative], [+1st], and [+Singular] before it can attach the /o/ to the Latin stem am- in order to generate amo 'I love'. This same capacity allows the MS component to reorder affixes, such as in Turkish gelir-ler-se and gelir-se-ler both of which mean 'if they come'.
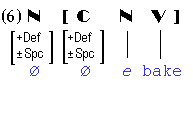
Let us imagine the inflectional realization of the input to baker illustrated in (5). The minimal projection of that structure, if it does not undergo L-derivation, would resemble (6).
I am assuming that the realizations of the pronoun one, i.e. someone, anyone, the one(s) result from the interplay of features [±Specific] and [±Definite]. Other treatments may be possible but this one serves the purposes of exemplification. Whatever the approach, the MS-module will have to interpret the lexical and inflectional features of the ultimate nodes and realize them as pronouns, i.e. the one/someone who bake-s. An LMBM MS-module with such a capacity would resemble the following diagram of a computational model of morphological spelling.
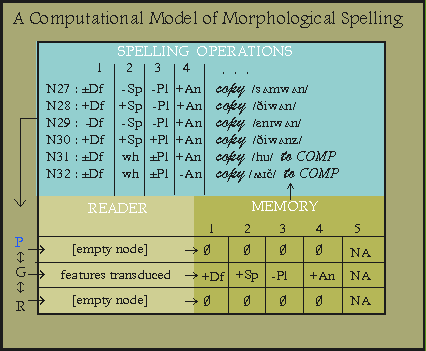
Notice the lexeme representation in the lower left; it comprises a phonological (P), a grammatical (G), and semantic (R) representation. The MS-module can read all three representations but can modify only P, given its purely phonological nature. These features first must be converted to those of the MS-module since MS-rules often need not know, say, whether the final segment of the stem is a /p/ or a /g/, but rather only whether it is a consonant or a voiceless consonant. That information is fed in ordered fashion to short-term memory. The MS-module also contains a list of rules which responds to the information in its memory. In this diagram only the grammatical information is relevant, so only it is represented. Notice that the features in the G-register of memory correspond one-one to the inflectional and lexical features of (6). The MS speller waits until the features in its memory correspond to the conditions on some operation. When they do, it obligatorily carries out that operation.
This brief introduction to LMBM has outlined the basic assumptions about (1) the lexicon, (2) lexical derivation rules, (3) inflectional derivation rules, and (4) morphological realization. The full theory is available in Beard (1995). Beard (1981, 1987) provides a general theory of morphological performance which distinguishes most types of extragrammatical derivational processes from those determined by grammar. The predictions of LMBM for a processing theory has been addressed in two preliminary papers, Beard (1986, 1989). Comments, questions, requests, and offers may be directed to rbeard at bucknell dot edu.